
Ausarbeitung
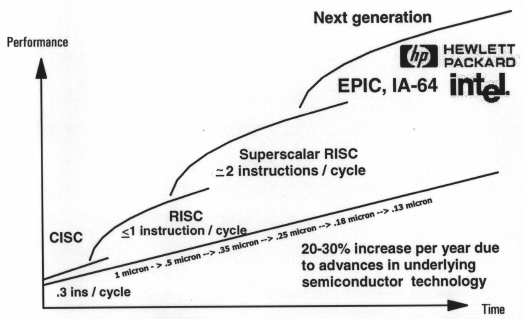
Bisherige Rechnersysteme (CISC, RISC) stossen langsam aber sicher an die Grenzen ihrer Leistungsfähigkeit und dessen, was technisch machbar/bezahlbar ist. Sie bearbeiten sequentiellen Code, der zudem bei CISC auch unterschiedlich lang ist und einer Dekodierung bedarf, und versuchen, diesen durch eigene Betriebsmittel zu schedulen, zu parallelisieren. Sie versuchen, mit Datenflussgraphen die Abhängigkeiten zwischen den Befehlen zu ermitteln und diese dann, wenn möglich, parallel oder gar völlig out-of-order auszuführen. Die Wahrung der Befehlsreihenfolge, aber auch die Abhängigkeiten bei dynamischeren Speicherzugriffen, die Absehbarkeit bedingter Sprünge und natürlich Speicherzugriffe selbst werden dabei mit zunehmendem Mass ein Problem. All diese Massnahmen kosten natürlich, Platz auf dem Chip, was die Ausbeute pro Wafer verringert, die Fehlerrate pro Chip erhöht und letztlich den Prozessor teuerer werden lässt, ganz zu schweigen davon, dass man all diese Einheiten nicht endlos beschleunigen und synchronisieren kann.
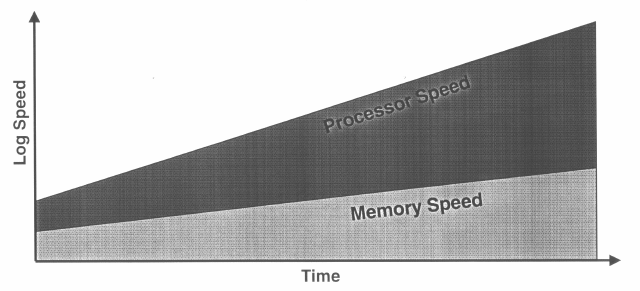
Ganz abgesehen von der eigentlichen Geschwindigkeit der Codebearbeitung, welche mit zunehmender Miniaturisierung und Optimierung nach Moors Gesetz stetig schneller wird, bleibt die Aufgabe, die zu bearbeitenden Daten erst einmal heranzuschaffen. Zwar ist es durchaus möglich, Prozessoren mit 2MB Cache zu bauen (Intel Server-Xeon, 135Mio Schaltungen on Die), aber spricht der Preis von 3.800 Dollar wohl seine eigene Sprache. Heutige Speicher sind einfach nicht schnell genug, um den Anforderungen eines Prozessors, nämlich die kontinuierlichen, ununterbrochenen Ausführung zu ermöglichen, zu genügen.
Während aktuelle Prozessoren Speicher mit einer Zugriffszeit von höchstens 1 - 1.5ns benötigen würden, haben heute kaufbare/bezahlbare SDRAMS gerade einmal 5-8ns. Zwar gibt es durchaus auch RDRAMS (Rambus), die zumindest in den Bereich von 800Mhz vorgestossen sind, jedoch spricht der Preis dieser Speicher wiederum eine deutliche Sprache.
Man spricht bei heute aktuellen Prozessoren von einer Befehlsausführrate von höchstens 1.5 - 3 (Quelle: HP/Intel), und das wie gesagt auch nur, dank ausgeklügelter, dynamischer Parallelisierung des sequentiell vorliegenden Codes, womit schon das Ende der Fahnenstange erreicht wäre. Daher auch die Notwendigkeit einer neuen Architektur, die diese Barriere von 3 Befehlen zu überwinden weiss.
Hatte man bisher nur Compiler, die die vorhandenen Befehle möglichst effektiv versuchten einzusetzen, wird man nun Compiler benötigen, die die Interna des Prozessors kennen, und auch beherrschen, um den Code höchst selbst zu parallelisieren und zu optimieren. Dazu stehen dem Compiler einige Hardware-Hilfsmittel zur Verfügung, die er allesamt selbst kontrollieren kann. Daher steht EPIC auch für EXPLICIT Parallel Instrcution Computing. Der Prozessor optimiert nichts mehr selbst, sondern führt nur noch aus.
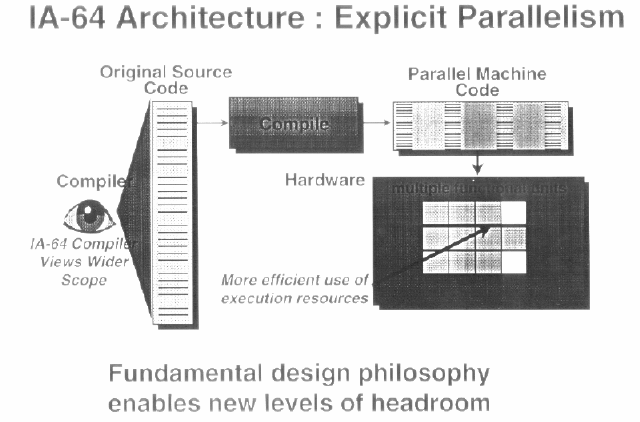
(Ein Vergleichbares Konzept hat auch Transmeta mit dem Crusoe entwickelt, der ebenfalls im Grunde aus einem VLIW Kern besteht, dem jedoch eine vorgeschaltete (Mikro-)Software die x86 Befehle vorkaut, optimiert, parallelisiert und dann erst vorwirft.
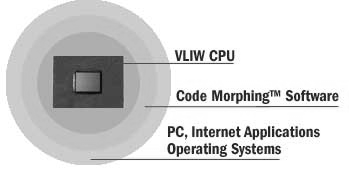
Jedoch geschieht dies beim Crusoe dynamisch und von mal zu mal zunehmend, bei EPIC jedoch nur vorher einmal im Compiler. Allerdings ist dieser Prozessor bereits seit Anfang-Mitte 2000 Produkt und auf dem Markt)
[Bisheriger Rechnersysteme... implizite Parallelität, linearer Code... speed gap zwischen speicher und proz ... Ende der Fahnenstange der internen Parallelisierbarkeit des Codes ... Jetzt: Optimierungen und Paralleliserung auf den Compiler verschoben, dem man die Mittel zur verfügung stellt.]
VLIW: Very Large Instruction Word. Eine Befehlseinheit besteht gleich aus mehreren Befehlen, die parallelisierbar, und somit 'am Stück' zu bearbeiten sind. Fallen einmal weniger Befehle an, als in eine Befehlseinheit passen würden, werden NOPs (No OPeration) eingefügt.
IA64: Intel Architecture 64. Die Intel Reincarnation/Bezeichnung für die EPIC-Technologie, die im Itanium den ersten Einsatz erfahren wird. Ein IA64 Prozessor wird IA64 und IA32-Code ausführen können, sowie über eine Umsetzung auch HP-PA-Code.
IA32: Intel Architecture 32. Die bisherige Intel-Architectur, gemeint sind alle 32Bit x86 Prozessoren, also vom 386er bis hin zum PentiumIII (IV).
EPIC: Explicit Parallel Instruction Computing. Die neue Architectur, die HP und Intel entwickelt haben (je nach Darstellung). Ein erweiterter VLIW Prozessor führt die Befehle aus, die ein optimierender Compiler statisch generiert und parallelisiert hat. Dafür stellt der Prozessor einige Hilfsmittel zur Verfügung (Predicates, Spekulative Befehle). Dynamisch optimiert wird nicht mehr.
RISC: Reduced Instruction Set Computing. Durch wenige, aber schnell ausführbare Befehle spart man eine aufwendige Dekodierung der Instruktionen, die man dann fest verdrahten kann. Heutige RISC-Prozessoren schedulen jedoch auch wieder dynamisch, womit der Vorteil kleinerer Prozessoren wieder dahin wäre. Ein Nachteil dieser Architektur ist aufgrund der gestiegenen Befehlszahl, die für die gleiche Aktion nötig ist, aufgeblähter Code und somit grössere Programme. Inkarnationen hierfür wären: ARM/StrongARM, i860, HP-PA, Pentium Pro (x86 Befehle wurden in RISC-Befehle übersetzt und ausgeführt, daher auch der grössere Cache on Chip).
Merced: Arbeitstitel für Intels ersten IA64 Prozessor. Er wurde später Itanium getauft.
Itanium: Erste Inkarnation von EPIC. Intels erster IA64 Prozessor.
PA-RISC: HP's Precision RISC Architecture, aka HP-PA.
ILP: Instruction Level Parallism. Die erreichbare Parallelität der Befehlsbearbeitung.
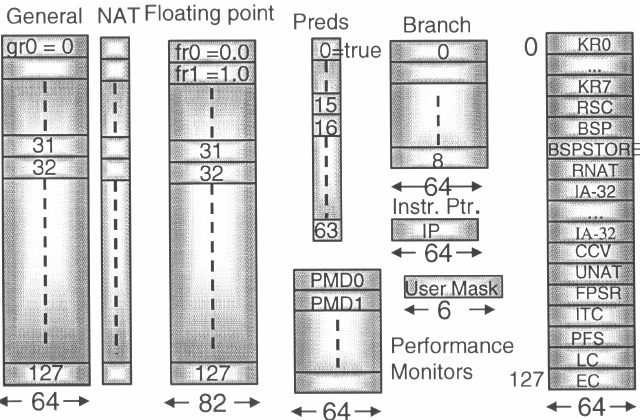
NAT: Not a Thing. Nicht definierte Codierungszustände von Fliesskommazahlen werden benutzt um Fehlerzustände zu kodieren. Das NAT-Bit ist das korrespondierende bei Integern.
ALU: Arithmetic Logical Unit. Die Prozessoreinheit, die den Befehl letztenendes ausführen muss.
Alpha: Processor von Digital/Compaq. Superscalarer Risc-Processor. Findet vor allem in Supercomputern Verwendung (Cray, Compaq, SGI u.a.) Aktuell: Alpha21264.
Probleme, die bei traditionellen Architekturen die Erweiterung zunehmend hemmen und die Konstruktion der Nachfolgegenerationen erschweren, sollten von vornherein vermieden werden. An genau diesen Problemen hangelt sich so die Entwicklung von EPIC entlang - welches vor allem ein erweitertes VLIW-Prinzip darstellt - als da wären dynmic-Branch-Prediction, Non-faulting-Loads und immidiate-Exception-Generation, Code Aufblähung durch Loop-Unrolling, Scope-Limitierung innerhalb der Code-Parallelisierung und Scheduling in Hardware. Ausserdem sollte die Berechnung jederzeit unterbrechbar und wieder anstossbar sein, was aufgrund der Nicht-Sichtbarkeit innerer Zustände, wie zum Beispiel dem Zustand der Pipelines oder auch dem internen Zustand der ALUs, der Branch Prediction etc., nur erschwert machbar ist. Zudem sollte natürlich vor allem der ILP (Instruction Level Parallelism) erhöht werden und der generierte Code auch binär kompatibel für mögliche Folgemodelle und Weiterentwicklungen bleiben.
Die andere Seite der Medaille war das immer weitere Auseinanderdriften der Geschwindigkeitsentwicklungen bei Speicher und Prozessoren, dem begegnet werden sollte. Bei heutigem Programmcode tritt durchschnittlich alle 9 Befehle ein Speicherzugriff auf. Wenn der Zugriff nicht auf Anhieb funktioniert hat, tritt eine exception auf, die behandelt werden will, oder aber die Bearbeitung wird so lange aufgeschoben, bis die Daten vorliegen. Dass dies die Bearbeitung nur ausbremst wird bei einer Verzögerung bei selbst einem L2-Zugriff von 25 Zyklen deutlich und erklärt auch, warum selbst modernste Prozessoren nur auf einen ILP von 1.5-3 kommen.
(Fehlt nur noch der Alpha, der jedoch auf einen ILP von 4-6 kommt, obwohl dieser auch nur mit Wasser kocht - dies jedoch wesentlich massiver als andere. Man kann es sich eben leisten...)
Um die Parallelisierung des Codes zu erhöhen, muss man zunächst einmal einen grösseren Teil des zu übersetzenden Codes kennen, um die Abhängigkeiten analysieren zu können und die Befehle so umordnen zu können, dass mehrere davon gleichzeitig ausführbar sind. Dieser Punkt ist jedoch nicht in Hardware zu realisieren, da man hier immer an technische und technologische Grenzen stossen wird, und wird dem optimierenden Compiler überlassen. Da man nun ohnehin von einem parallelisierenden Compiler ausgeht, muss man diesem auch die notwendigen Hilfsmittel zur Verfügung stellen, um seine Aufgabe so effizient wie möglich erledigen zu können.
Predikatierung und Spekulierung heissen hier die Zauberworte. Ersteres wird benutzt, um Code, der eigentlich nicht parallel auszuführen ist, da er beispielsweise von einer laufzeitbedingten Bedingung abhängig ist, dennoch schon einmal spekulativ auszuführen. Traditionelle Architekturen benutzen hier eine Sprungvorhersage, um den möglicherweise folgenden Code out of order auszuführen und als gültig zu erklären, wenn der Sprung tatsächlich gültig war. Jedoch kann hier die Vorhersage falsch gewesen sein und die Berechnung somit über den Haufen geworfen werden. Wertvolle Zyklen gehen dann beim Nachladen der gültigen Sprungaddresse und dem abermaligen Füllen der Pipeline verloren.
Mit binären Predicates wird die Gültigkeit von Code markiert. Der Prozessor führt zwar allen Code aus, den er geliefert bekommt, jedoch wird nur derjenige für gültig erklärt, der ein gültiges Predicate enthält, oder aber zumindest nachgeliefert bekommt. Paradebeispiele hierfür sind IF-THEN-ELSE Konstrukte:
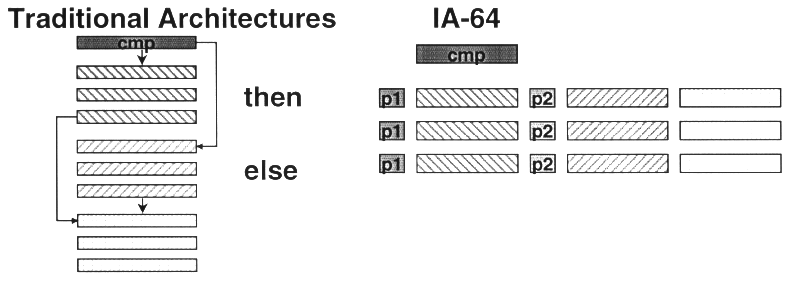
(Die Zuweisung des Vergleichsergebnisses auf die Predicates muss kein Entweder-Oder sein. Es können auch beide Fälle gleichzeitig gültig erklärt werden!) Der definitive Vorteil ist dabei natürlich, dass die Befehlspipeline die ganze Zeit gefüllt bleibt und auch kein Platz für Vorhersagemechanismen verschwendet werden muss, da es keine Vorhersage gibt, ausser der des Compilers.
Der andere Teil, nämlich die Spekulation, betrifft vor allem den Umgang mit Speicherzugriffen. In der traditionellen Programmierung lade ich ein Datum und verwende es. Ich nehme keine grosse Rücksicht darauf, wie lange dieser Zugriff eigentlich dauert, denn der Prozessor wird die Befehle ohnehin nach seinen Möglichkeiten umstellen, was natürlich nicht immer funktionieren kann, nicht nur aufgrund der Unübersichtlichkeit des Codes, sondern auch wegen Speicher-Hazards.
Die erste Art von Spekulation die ich hier vorstellen möchte, geht die Speichergeschwindigkeit an. Man stellt dem Compiler Befehle zur Verfügung, mit denen er das Laden von Daten spekulativ nach vorne verschieben kann und später nur noch nachfragen muss, ob denn das Laden eigentlich funktioniert hat, ob die Daten denn definitiv anliegen und korrekt sind. Sollten sie dann noch immer nicht anliegen, kann man immer noch nach einer Exception schreien, die dann wiederum durch ganz normale Ladebefehle (non-faulting loads) die Daten laden muss.
Da bei all diesen spekulativen Ladebefehlen immer die Gültigkeit der Daten abgefragt und bei möglichen Folgeberechnungen weiter übertragen wird, ist es so auch möglich mehrere spekulative loads auszuführen, ohne diese direkt abzufragen. Stattdessen fragt man durch einen Check-Befehl (der sonst auf die geladenen Daten zugreifen würde) nur das Ergebnis ab. Dies spart wiederum den Code multipler Checks ein.
Für die Gültigkeitsprüfung bei statischen Registern, deren Belegung der Compiler zuvor planen kann, gibt es bei den GRs ein zusätzliches Bit, das 65ste. Bei FPRs ist es eine NAT (Not A Thing), also eine innerhalb der Codierung für Fliesskommazahlen unzulässige Bitkombination. Bei Daten jedoch, deren Gültigkeit unbekannt ist, also eine Speicherstelle, die in einem Register abgelegt ist, funktioniert dies natürlich nicht derart trivial. Für die Auflösung solcher Speicher-Hazards (read-after-write etc.) gibts es die ALAT (A Look Alike Table). Sie besteht aus der Registernummer, der physischen Addresse und der Grösse der gelesenen Daten.

Liest nun ein Register von einer Speicherstelle, so wird diese in der ALAT eingetragen. Ein weiterer Leseversuch verändert diesen Eintrag nicht. Wenn jedoch in den Speicher geschrieben wird, wird zunächst in der ALAT ein entsprechender Eintrag gesucht. Wird einer gefunden, so wird dieser gelöscht. Wird also für ein Register kein Eintrag vorgefunden, so sind diese Daten ungültig und müssen unspekulativ nachgeladen werden.
Die zweite Art der Spekulation ist die Control-Spekulation. Dies betrifft vor allem die Predikatierung der Befehle, die spekulativ mit einem Predikat versehen werden, das zu einem (viel) späteren Zeitpunkt erst gültig gesetzt wird und somit die schon ausgeführte Berechnung ebenfalls als gültig erklärt. Ziel dieser Art der Spekulation ist es, die Beweglichkeit von Befehlsblöcken zu erhöhen. Es reicht oftmals nicht, sie einfach nur vor einen anderen Befehl zu stellen, um den ILP zu erhöhen. Mit dieser Vorgehensweise der Block-Predikatierung und Verschiebung kann man die Befehle viel weiter nach vorne verschieben, um damit spekulativ beispielsweise Löcher in zuvor nicht vollständig gefüllten Befehlsblöcken zu schliessen, oder aber eben auch Speicherzugriffe unkritisch ausführen zu können. Alle Befehle, die dann in diesem verschobenen Befehlsblock vorkommen sind dann natürlich wiederum spekulativ.
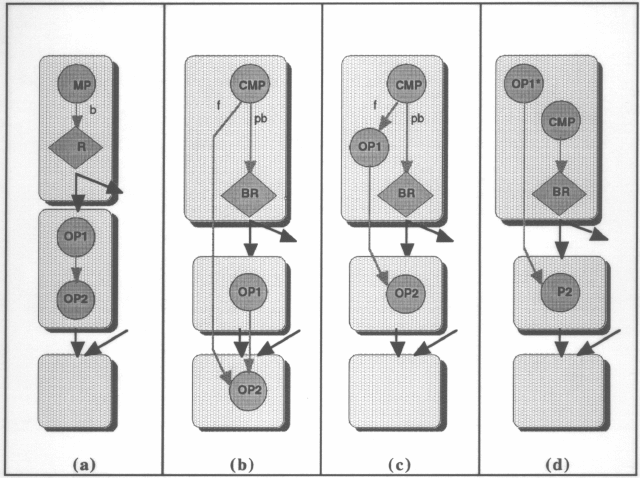
Allen Arten von Spekulativen Befehlen ist gemeinsam, dass sie Ausnahmenfehler nicht sofort melden, wie dies unmittelbare Befehle machen würden. Die Fehler werden erst gemeldet, wenn nach ihnen ge-chck-ed wird. Ein Check-Befehl kann beliebig spät nach den spekulativen Befehlen kommen, da die Fehler, die sich durch die Spekulation einschleichen können (NAT-Fehler etc.) auch als solche erhalten bleiben und jederzeit abgefragt werden können. Unspekulative Befehle melden ihre Exception sofort.
Wird dann der Fehler behandelt, kommt wiederum ganz normaler, unspekulativer Code zur Behandlung zur Ausführung. Dieser kann dann natürlich beliebig komplex sein, je nachdem was für Operationen zu korrigieren sind.
Als Viertes zu nennen bleibt die Möglichkeit des Register Rotation. Alle drei Gruppen von Registern, GRs, FPRs und PRs, können in einem, durch den Compiler bestimmten Bereich rotieren. Besonders deutlich wird der Nutzen dieser Möglichkeit am Beispiel einer einfachen Copy-Aktion. Man liest (wenn möglich eben spekulativ und parallel predikatiert) von den Addressen immer auf das gleiche Register, schreibt im nächsten Befehl von diesem Register wieder in den Speicher weg. Dadurch, dass dieses Register jedoch nicht immer das gleiche ist, sondern ein Bereich der Registerbank unter diesem Register rotiert, wird der spekulativ verzögerte Zugriff möglich. (Mehr dazu im nächsten Kapitel)
Da für solche Aktionen genügend Register zur Verfügung stehen müssen, muss die neue Architektur auch ausreichend davon besitzen (mehr dazu später).
Desweiteren muss sichergestellt werden, welche Hardware-Einheit welchen Befehl zugeteilt bekommt. Da der Compiler die gesamte Kontrolle übernehmen muss, muss er auch dies können, da auch nicht alle Befehle können auf allen Einheiten ausführbar sein können (zum Beispiel TBit) und der Prozessor so viel Intelligenz nicht mehr besitzen soll. Bei einer Vollauslastung aller Einheiten müsste er in solch einer Situation andernfalls einen Zyklus aussetzen, bis die nötige Ressource wieder frei ist, was dem Grundsatz des ILP widerspräche. Für diese Zuteilung werden die letzten Bits eines Instruktionswortes benutzt, mit denen direkt die jeweiligen Einheiten ausgewählt werden.
Ebenfalls Teil der EPIC-Philosophie ist die Garantie der Ausführungszeiten der einzelnen Befehle.
Auch die Kompatibilität ist in EPIC sehr vollständig definiert. Da es nicht nur Befehle gibt, die nur einen Zyklus verbrauchen (oder auch gar keinen, wie ein use- oder check-Befehl), sondern auch solche mit mehreren, muss für alle Prozessoren die Lauffähigkeit des Codes sichergestellt sein. Da gerade die spekulativen Befehle sehr timing-sensitiv sind und im Falle einer uneingerechneten Exception beispielsweise Echtzeiteigenschaften von Betriebsystemen verletzt werden könnten, wird die Auswahl der verbrauchbaren Recheneinheiten (Überbegriff für Zyklen/Zeiteinheiten) ebenfalls dem Compiler ermöglicht. Ihm steht also fast die komplette Konfiguration des Prozessors zu Diensten, dessen Geschwindigkeit er in gewissen Grenzen definieren kann.
Dies soll die Möglichkeit kundenspezifischer Optimierung, beispielsweise auf Kosten oder Stromverbrauch was die tempoeigenschaften ja verändern kann, ermöglichen ohne dabei zu riskieren, dass vorhandener Code nicht mehr läuft. Inwiefern dies jedoch in den Prozessoren der ersten Generation der Fall sein wird ist noch nicht abzusehen. Zumindest beim Itanium wird auf diesen Punkt nicht weiter eingegangen.
[gesamtes Scheduling und optimierung wird dem Compiler überlassen, dem man die nötigen Hilfsmittel zur Seite stellt. Volle Kontrolle und Übersicht über die Hardware und die gesamten Betriebsmittel.
Predication ... if-then-else in einem befehl...
Speculation ... load.a load.d load.s use check.a chech.s
(Register Rotation, viele Register)
Flags für Hardware-Zuteilung (5Bit)
ALAT - Tabelle für Speicher-Register-Hazards
NAT-Bits für spekulations-erfolg
Garantierte Ausführungszeiten/Verhältnisse der Befehle untereinander
Garantierte Zeiten der Registerzugriffe der Befehle, die mehr als einen Zyklus brauchen]
Der Itanium wird der erste Prozessor sein, der EPIC in Gestalt von IA64 dem Markt eröffnen wird.
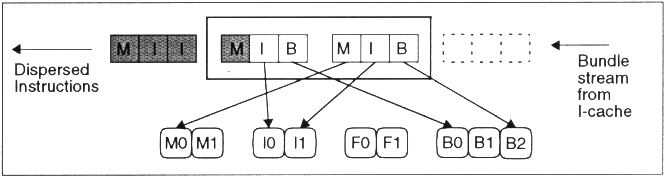
Ein VLIW-Befehl von 128Bit besteht somit aus drei Befehlen von je 41Bit, zuzüglich 5Bits zur Auswahl der Befehlszusammensetzung. Jeder Befehl besteht aus 6Bits für das Prädikat und drei mal 7Bits für Operanden.

Er stellt 2 Memory, 2 Integer, 2 Fliesskomma und 3 Branch Einheiten für Speicherbefehle zur Verfügung.

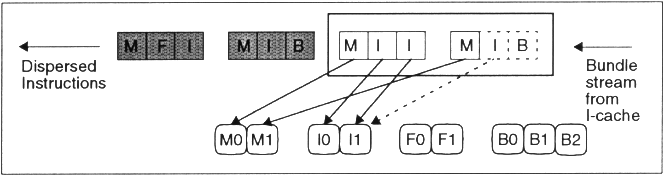
Die 5 Bits des Templates zeigen an, welcher Art die Befehle sind um schon vor der Decodierung eine Zuweisung zu ermöglichen. Anhand dieser Bits wird die Zusammensetzung des Befehlspacketes aus einer Liste von Moeglichkeiten ausgewaehlt, also zum Beispiel: MFI, MIB, MII, MBB etc.
(Der Alpha benutzt uebrigens diese Art der Vorweg-Befehlsinhaltsangabe ebenfalls, erstellt jedoch erst zur Laufzeit eine 3Bit Flag-Tabelle für jeden Befehl)
Diese Befehlspackete werden je paarweise betrachtet und auf die ausgewählten Einheiten verteilt.
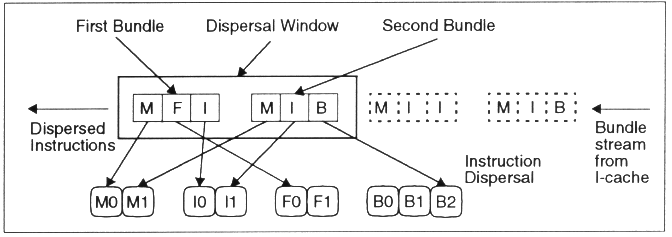
Kann ein Befehlspacket nicht vollständig versorgt werden, so kommt bei der nächsten Betrachtung nur ein neues Packet hinzu.
 1.
1.
 2.
2.
Ausserdem gibt es ein paar Ausnahmen, nach denen immer gesplittet wird, als da wären alle Befehle vom Typ Semaphore, inval, invala.e, halt.mf, mf.a. Desweiteren natürlich, wenn die freie ALU den Befehl nicht ausführen kann. So kann z.B. I1 nicht jeden Befehl ausführen, z.B. TBIT, SYS_IO, MMMUL.
Der Prozessor stellt 128 64Bit Integer-, 128 82Bit Fliesskomma-Register sowie 64 1Bit Predikat-Register zur Verfügung, um ausreichend Raum für Register-Rotation zu haben. Von diesen 128 Registern sind jedoch die unteren 32 statisch und nicht rotierbar.
Dieser massive Ressourceneinsatz ist durch die gegebene Möglichkeit der Register-Rotation, sowie der spekulativen Befehle, die ebenfalls auf irgendetwas arbeiten müssen, begründet.
Der Cache ist exclusiv ausgelegt, das heisst dass im L2 Cache keine Daten vorliegen, die schon im L3 liegen. Damit wird viel Verwaltungsaufwand vermieden um die beiden Caches zu halten. Fliesskommabefehle greifen jedoch beim laden nicht auf den L1 Cache, sondern direkt auf den L2-Cache zu. Der L1-Cache ist in Daten und Instructions-Caches unterteilt und kann 2 Speicherzugriffe per-clock ausführen, unabhängig von der Art des Zugriffs (read/write).
Dass Intel daran interessiert ist, dass auch 'normale' x86-Programme auf den neuen Prozessoren laufen dürfte klar sein. Darum wird er auch solchen IA32 Code direkt ausführen können. Er wird also eine Dekodiereinheit haben müssen, die erkennt, dass es sich nicht um einen VLIW-Code, sondern um sequentiellen Code handelt.
Mitentwickler HP möchte ebenfalls seine Programme beisteuern, jedoch geschieht die Umsetzung hier über Software.